Simulation for Evaluating Robot Policies Should Be
Asynchronous
and
Real-Time

Simulation is an indispensable tool for evaluating robot algorithms in a safe and scalable manner.
However, current simulation benchmarks introduce an artificial sim-to-real gap by running robot policies synchronously —
pausing the simulation to let the policy “think” for as long as it needs before executing actions.
But real world physics does not wait for policy inference.
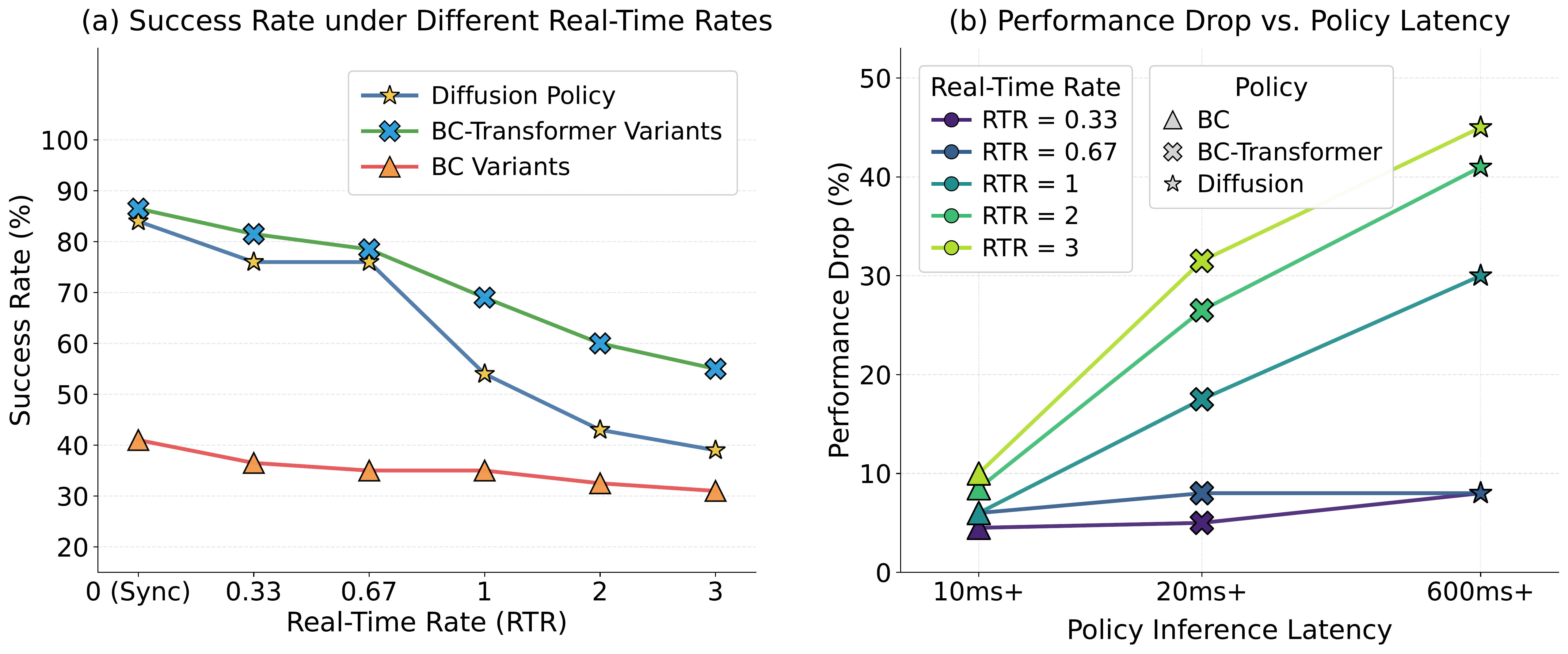
Synchronous evaluation provides an unfair advantage to heavyweight policies with large backbones or iterative denoising
that may be performant, but are too slow in the real world.
We introduce AsyncRoboSim: a protocol to make any robotic simulation benchmark asynchronous
by running the simulator and policy in parallel threads.
The simulator runs in real time and communicates with the policy via shared inter-process queues for observations and actions.
Importantly, the simulation rate is decoupled from the speed at which the policy consumes observations and produces actions.
We instantiate our approach in robosuite, the underlying simulation framework for many robotic benchmarks
that can automatically inherit our asynchronous implementation.
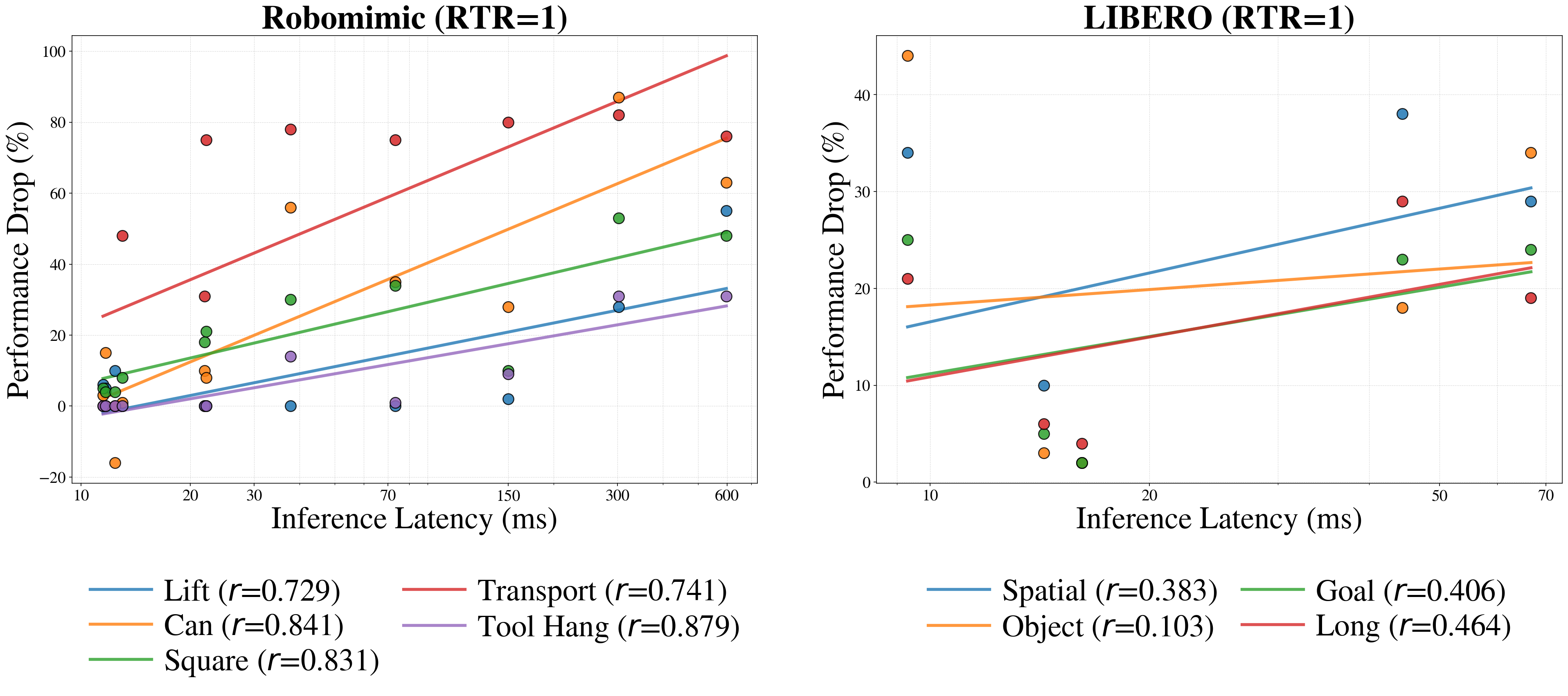
We show that the performance of standard manipulation tasks in AsyncRoboSim is significantly more correlated
with real-world performance than conventional synchronous simulation.
Realtime, asynchronous simulation naturally reflects inference latency in task performance metrics and also aids debugging.
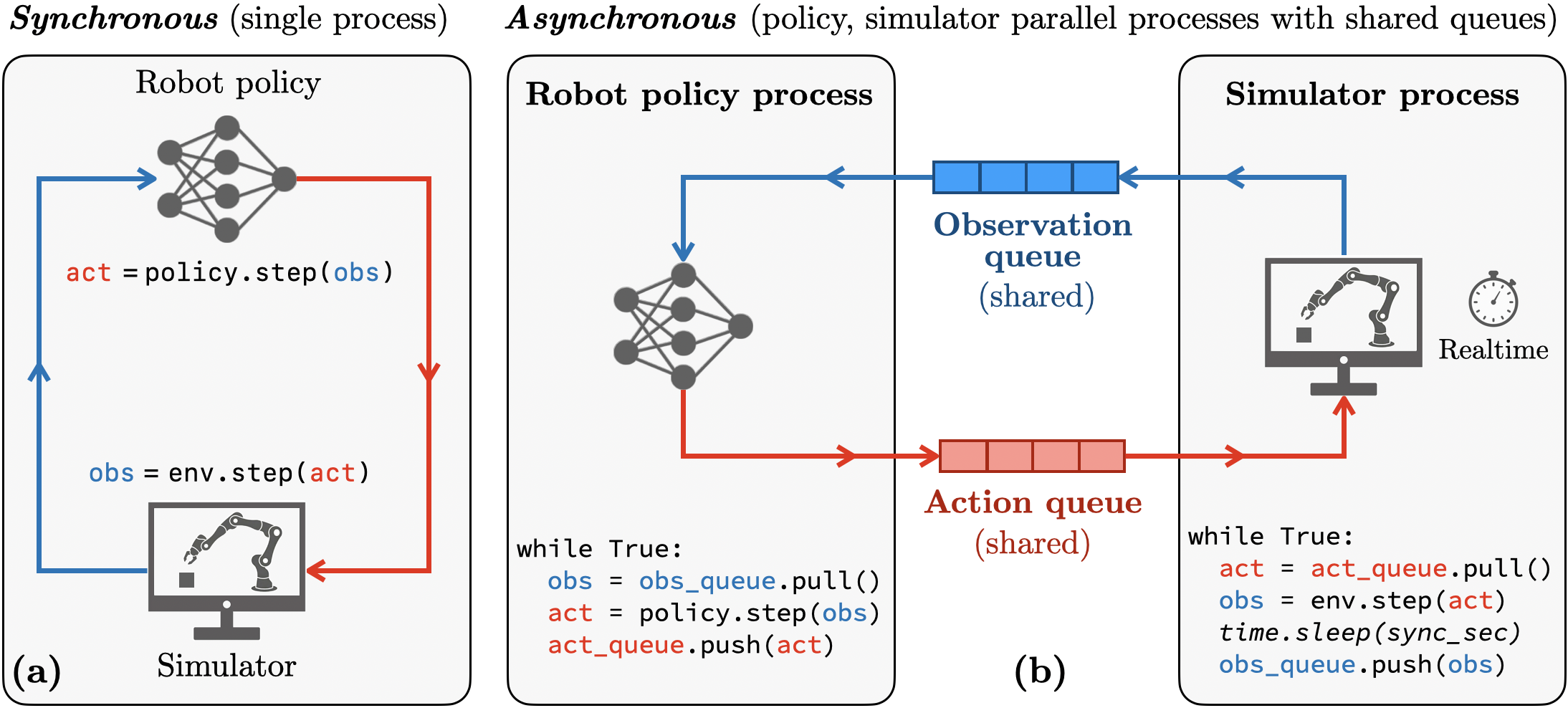
Left — Synchronous: the simulator alternates between policy inference and physics steps
in a single process, freezing physics while the policy is “thinking.”
Latency is hidden, so the motion looks deceptively smooth in simulation no matter how slow the policy is.
Right — Asynchronous: the policy and simulator run as separate parallel processes
that continuously communicate and interact with each other via shared observation and action queues.
The simulator advances physics in real time and never waits for the policy —
if the next action is not ready, the simulator keeps executing the most recent one.
This exposes the true inference latency of the diffusion policy that visibly “jitters” at chunk boundaries where denoising occurs,
mirroring how latency manifests on a real robot.
The real-time rate (RTR) is a tunable knob that sets the speed of the simulation relative to the wall clock, letting us evaluate a policy under different hardware and compute budgets without changing the policy. RTR = 1 (center) runs physics at true real time, our default. RTR > 1 (right) advances physics faster than real time, emulating scarcer compute — e.g. an edge device or a heavily loaded workstation — so the policy’s latency is effectively amplified. RTR < 1 (left) advances physics slower than real time, emulating more abundant compute that the policy can keep up with more easily. All clips show asynchronous simulation with action chunk = 16. Increasing the RTR (faster simulation) lowers task success and widens the gap between synchronous and asynchronous simulation, since the policy has relatively less time to react.




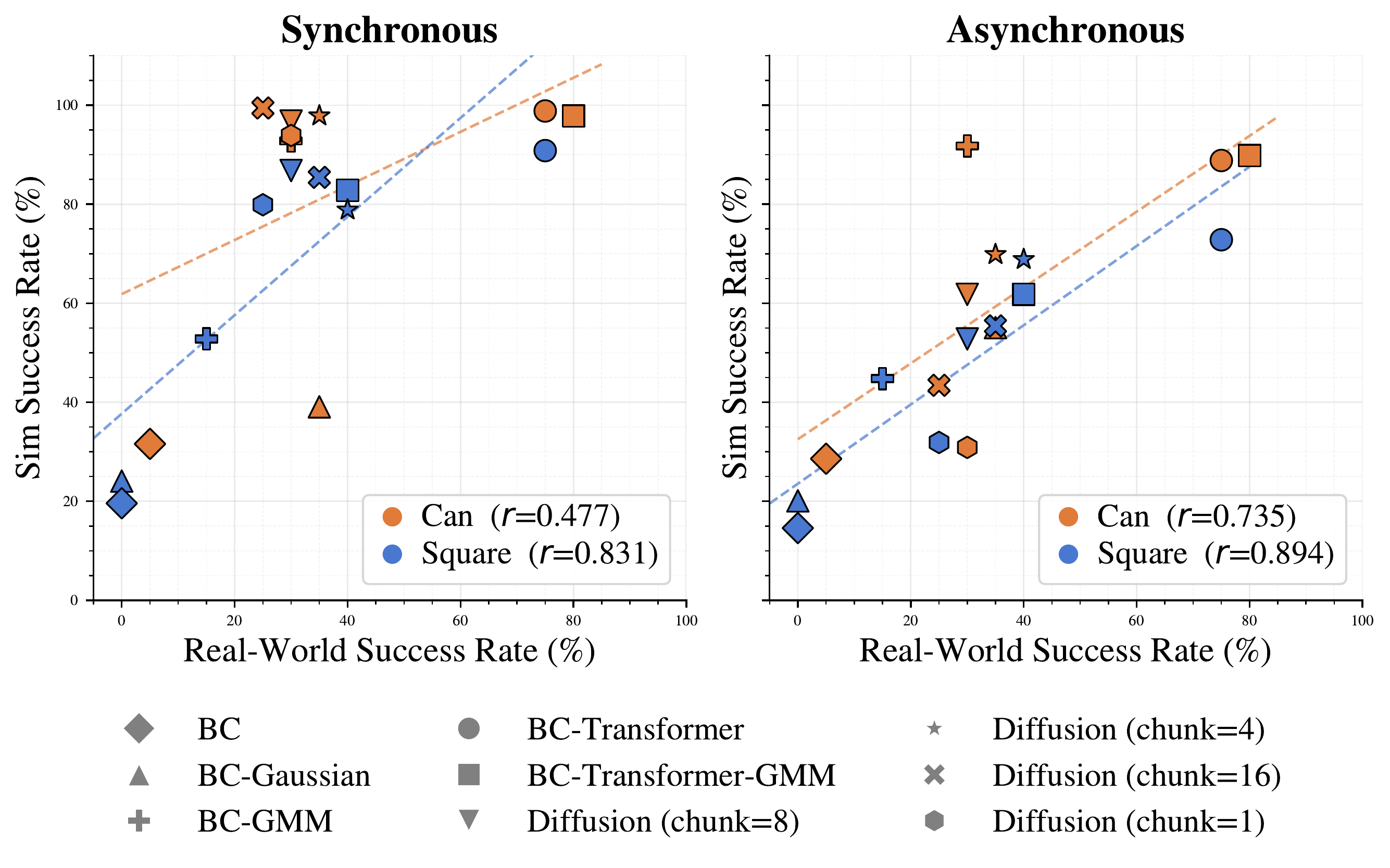
We reproduce the Can and Square tasks from Robomimic on a real Franka Research 3 robot, using the same objects and 3D-printed tools as their simulated counterparts. Can is a pick-and-place task requiring robust object transport across spatial and height variation, while Square is a contact-rich precision task that inserts a square nut onto a peg with tight geometric tolerance. Both demos run a diffusion policy predicting action chunks of 16 (chunk = 16). These real-world rollouts are the ground-truth that we compare against. We find that performance in asynchronous simulation is significantly more correlated with this real-world performance than conventional synchronous simulation.
| Task | Condition | Pearson r | Spearman ρ | Pairwise Acc. |
|---|---|---|---|---|
| Can | Synchronous sim | 0.477 | 0.485 | 0.724 |
| Asynchronous sim | 0.735 | 0.664 | 0.812 | |
| Improvement (sync → async) | +0.258 | +0.179 | +0.088 | |
| Square | Synchronous sim | 0.831 | 0.782 | 0.824 |
| Asynchronous sim | 0.894 | 0.975 | 0.971 | |
| Improvement (sync → async) | +0.063 | +0.193 | +0.147 |
We quantify how well simulation predicts the real world using three metrics: Pearson r (linear correlation, sensitive to the magnitude of differences), Spearman ρ (rank correlation), and Pairwise Accuracy (the fraction of policy pairs whose real-world ordering simulation gets right). Across both tasks and all three metrics, asynchronous simulation correlates more strongly with real-world performance than conventional synchronous simulation — for example, Pearson r rises from 0.477 to 0.735 on Can and from 0.831 to 0.894 on Square. In other words, asynchronous simulation is a better predictor of which policy will actually perform better on the real robot.